Spring Boot에서 Redis Cache 적용하기
조금 지났지만, Locust라는 도구를 통해 API 부하테스트를 진행한 적이 있다. 그 때 발생했던 특정 API의 응답 지연을 해결하기 위해 Redis Cache를 적용한 경험을 공유하려고 한다.
Cache란?
Cache는 데이터나 값을 미리 복사해두어서 빠르게 접근할 수 있도록 하는 메모리 영역을 말한다.
기본적으로 RDB는 디스크에 저장되어 있기 때문에, 단순히 메모리에 저장되어 있는 Redis와는 비교도 안되게 빠른 속도로 가져올 수 있다.
물론 캐시의 전략에 따라 세부적인 흐름은 흐름은 다를 수 있지만 일반적인 캐시 전략인 Look-Aside Cache를 기준으로 설명하면 아래와 같다
Cache Hit
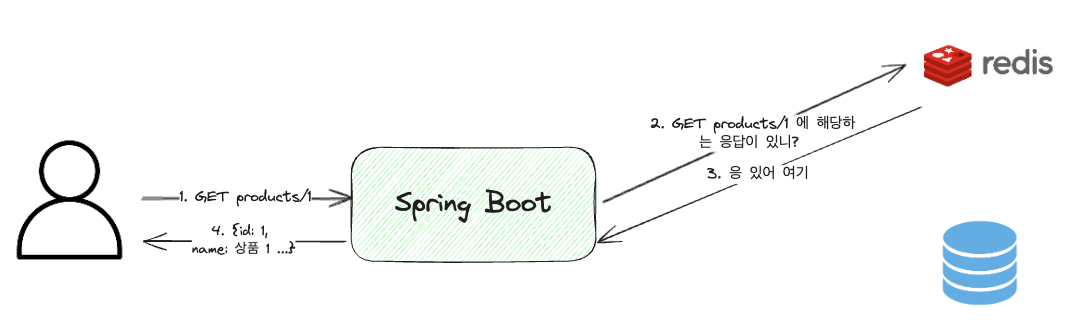
Cache Hit, 즉 캐시에 데이터가 존재하는 경우를 말한다. 이 경우, 캐시에 저장된 데이터를 가져와서 사용하기 때문에, 데이터를 가져오는데 걸리는 시간이 매우 빠르다.
Cache Miss
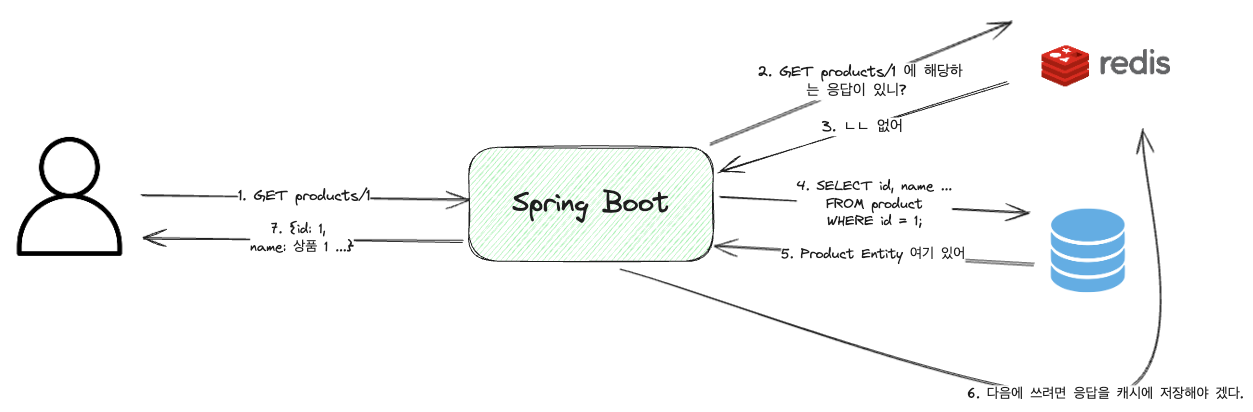
Cache Miss, 즉 캐시에 데이터가 존재하지 않는 경우를 말한다. 이 경우, 데이터를 가져오기 위해 데이터베이스나 다른 저장소에서 데이터를 가져오며, Redis에서 데이터를 체크하고, DB에서 데이터를 가져오고, 응답을 다시 Redis에 저장하는 과정을 거치게 된다.
따라서 이 경우 오히려 캐시가 없는 경우보다 더 느릴 수 있다.
Redis를 캐시로 사용하는 이유
Redis는 Remote Dictionary Server의 약자로, 메모리 기반의 Key-Value 구조를 가지고 있는 오픈소스 데이터베이스이다.
말 그대로 데이터 베이스라고 보면 된다.
일반적으로 RDB에서 데이터를 가져온다 하더라도 인덱싱이 잘 되어있다면, 데이터를 빠르게 가져오는데에 큰 문제는 없다.
다만 일반적으로 검색에 대한 결과값, 페이징 등 쿼리를 통한 결과 값 등은 꽤 큰 양의 연산을 요구하기 때문에, 이러한 결과값을 캐시로 저장해두고, 재 사용하는 것이다.
Spring Boot에서 Redis Cache 적용하기
1. 의존성 추가
먼저 Redis를 사용하기 위한 의존성을 추가해야 한다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'2. Redis 설정 추가
Redis에 연결을 위한 설정을 추가해야 한다.
@RequiredArgsConstructor
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
var redisTemplate = new RedisTemplate<String, Object>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
}먼저 redisConnectionFactory()이다 Redis에 연결을 위한 ConnectionFactory를 생성하며, LettuceConnectionFactory를 사용하였다.
일반적으로 Redis를 연결하는 Java 클라이언트로는 크게 Jedis와 Lettuce가 있는데, Lettuce가 비동기 처리를 지원하고, Netty를 사용하기 때문에 더 빠르다고 한다.
redisTemplate()은 Redis에 데이터를 저장하고 가져오기 위한 Template이다. setKeySerializer(), setValueSerializer()를 통해 Key와 Value의 Serializer를 설정해주었다.
간단하게 StringRedisSerializer를 사용하였다.
3. Cache 설정 추가
@Configuration
@EnableCaching
public class CacheConfig {
private Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer() {
var objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
objectMapper.enable(MapperFeature.ACCEPT_CASE_INSENSITIVE_ENUMS);
objectMapper.configure(
JsonReadFeature.ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER.mappedFeature(), true);
objectMapper.activateDefaultTyping(
objectMapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.EVERYTHING,
JsonTypeInfo.As.WRAPPER_OBJECT
);
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return new Jackson2JsonRedisSerializer<>(objectMapper, Object.class);
}
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration defaultCacheConfig =
RedisCacheConfiguration.defaultCacheConfig()
// TTL 설정 (예: 60초)
.entryTtl(Duration.ofSeconds(60))
// null 값 캐싱 방지
.disableCachingNullValues()
// key 직렬화
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer()))
// value 직렬화
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
jackson2JsonRedisSerializer()));
return RedisCacheManager
.builder(connectionFactory)
.cacheDefaults(defaultCacheConfig)
.build();
}
}Cache를 설정하기 위해 CacheConfig 클래스를 생성하였다.
jackson2JsonRedisSerializer()메서드는Jackson2JsonRedisSerializer를 생성하며, ObjectMapper를 통해 JSON 직렬화를 설정해주었다.registerModule()을 통해JavaTimeModule을 등록하였다. 이는 Java 8의 Date/Time API를 문제없이 직렬화/역직렬화하기 위함이다. 이걸 설정하지 않으면java.time패키지의 객체를 직렬화할 때 다음과 같은 에러가 발생한다.com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class java.time.LocalDateTime and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS)disable()을 통해WRITE_DATES_AS_TIMESTAMPS를 비활성화하였다. 이는 Date/Time 객체를 Timestamp로 직렬화하지 않도록 설정한 것이다.enable()을 통해ACCEPT_CASE_INSENSITIVE_ENUMS를 활성화하였다. 이는 Enum의 대소문자 구분을 무시하도록 설정한 것이다.configure()을 통해ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER를 활성화하였다. 이는 JSON 문자열에서 백슬래시를 이스케이프할 수 있도록 설정한 것이다.activateDefaultTyping()을 통해EVERYTHING을 설정하였다. 이는 모든 객체에 대한 타입 정보를 직렬화하도록 설정한 것이다.- 이를 설정하면 JSON 을 저장할 때
@class필드가 JSON에 추가되어 모든 객체에 대한 타입 정보를 저장할 수 있다. 이를 통해 객체를 역직렬화할 때 타입 정보를 참조할 수 있다.
단 이 방법의 경우, 타입의 위치를 변경한다던가하는 경우 해당 타입을 인식하지 못하는 문제가 생기므로, 배포 시 캐시를 날려준다던가 하는 방법을 고려해야 한다.
- 이를 설정하면 JSON 을 저장할 때
setSerializationInclusion()을 통해NON_NULL을 설정하였다. 이는 null 값이 포함된 필드를 직렬화하지 않도록 설정한 것이다.
cacheManager()메서드는RedisCacheManager를 생성하며, 이는 Redis에 캐시를 저장하고 가져올 때의 세부 설정을 담당한다.defaultCacheConfig()를 통해 기본 캐시 설정을 가져오며,entryTtl()을 통해 캐시의 TTL을 설정하였다. 여기서는 60초로 설정하였다. (너무 길게 설정할 경우 캐시와 실제 데이터의 불일치가 발생할 수 있으므로 캐시 시간 및 캐시 업데이트 전략을 신중하게 설정해야 한다.)
4. Cacheable, CacheEvict, CachePut 사용하기
@Cacheable
@Cacheable 어노테이션은 메서드의 결과를 캐시에 저장하고, 같은 파라미터로 호출될 때 캐시된 결과를 반환한다.
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
}@Cacheable 어노테이션은 캐시를 사용할 메서드에 추가하며, value를 통해 캐시 이름을 설정하고, key를 통해 캐시 키를 설정한다.
@CacheEvict
@CacheEvict 어노테이션은 해당 메서드 호출 시 캐시에서 데이터를 삭제한다.
리스트 조회 같은 경우 생성, 수정이나, 삭제가 발생할 때 어떤 데이터가 리스트 조회에 영향을 끼칠 지 알 기 어렵기 때문에, 캐시를 삭제하도록 전략을 설정할 수 있다.
단건조회 API의 캐시라도, 특정 ID값의 데이터가 변경되었을 때 캐시를 삭제하도록 하는 것이 안전할 것이다
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # 리스트로 조회하는 API가 없다면 굳이 지정할 필요는 없다
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
}@CacheEvict 어노테이션은 캐시를 삭제할 메서드에 추가하며, value를 통해 캐시 이름을 설정하고, allEntries를 통해 모든 캐시를 삭제할지 여부를 설정한다.
- 단건 조회만 존재한다면
key를 통해 특정 키의 캐시만 삭제할 수 있다.
@CachePut
@CachePut 어노테이션은 메서드의 결과를 캐시에 저장하고, 메서드를 호출하지 않고 캐시된 결과를 반환한다.
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@GetMapping("/products")
@Cacheable(value = "product")
public ListProductsResponse listProducts() {
return productService.listProducts();
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # 리스트로 조회하는 API가 없다면 굳이 지정할 필요는 없다. 단건 조회가 있다면 CachePut을 사용하는 것도 방법일 것이다.
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
@PutMapping("/products/{id}")
@CachePut(value = "product", key = "#id")
public Product updateProduct(@PathVariable Long id, @RequestBody Product product) {
return productService.updateProduct(id, product);
}
}@CachePut 어노테이션은 캐시를 갱신할 메서드에 추가하며, value를 통해 캐시 이름을 설정하고, key를 통해 캐시 키를 설정한다.
캐시는 무조건 사용해야 할까?
데이터가 많으면 많을 수록, 동일한 응답을 여러번 하는 경우가 많을 수록 연산이 복잡하면 복잡할 수록 캐시를 사용하는 것이 좋다.
일반적으로 이미지, 동영상 등의 정적 데이터는 변경되는 경우가 매우 적기때문에 대다수의 브라우저, CDN에서도 캐시를 사용한다.
하지만, 데이터가 자주 변경되는 경우, 캐시를 사용하면 안되는 경우도 있다. 오히려 실시간성이 중요한 데이터 (예: 계좌 잔액, 배송 정보 등) 같은 경우는 캐시를 사용하지 않는 편이 훨씬 이로울 것이다. (데이터 불일치를 해결하는 것이 더 힘들 수 있기 때문이다.)
결국 캐시를 사용할지 말지는 데이터의 특성, 사용자의 행동 패턴, 서비스의 특성 등을 고려해야 하며, 캐시 시간, 캐시 업데이트 전략 등도 이런 부분을 매우 신중하게 고려해야 한다.